
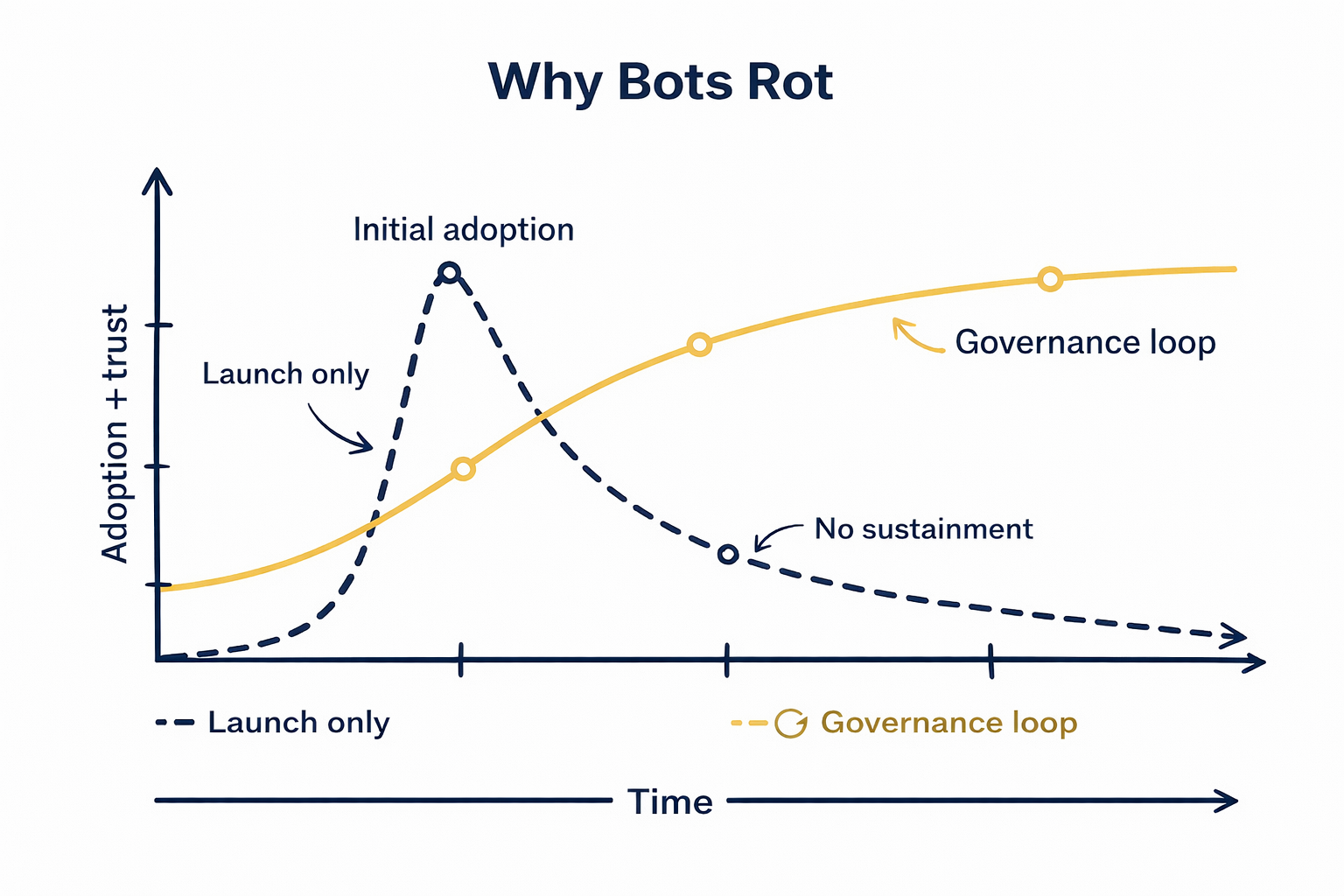
Week one feels sharp. Week six feels off. By month three, users have learned the lesson. The bot is useful for a couple of things, and unreliable for everything else. Trust drops, adoption stalls, and people route around it back to email, phone, or whatever shortcut still works.
That rot is rarely a technology problem. It’s a governance problem.
Not the kind of governance that looks like a quarterly committee. For conversational ITSM and GenAI, governance is a feedback loop: observe, decide, change, release, verify. If the loop is weak, the bot rots. If the loop is strong, the bot compounds.
Earlier posts in this series:
• The Death of the Destination Portal
• The Inversion: Moving from Portal Centric to People Centric Service
• The Core Journey Launch Strategy
• The Anatomy of a High Trust Virtual Agent
This final post is about sustainment. How you stop a good launch turning into shelfware.
Governance is a loop, not a committee
A committee is slow and opinion driven. A governance loop is fast and evidence driven.
A simple loop has four steps:
1. Observe what users asked, what the bot did, and where it failed.
2. Decide what to change, using agreed rules rather than the loudest voice.
3. Change the real cause: knowledge, routing, training, automation, handoff, guardrails.
4. Release quickly, verify, and measure again.
Your assistant is a front door sitting on top of a warehouse: services, knowledge, approvals, integrations, routing rules. When the warehouse changes and the bot doesn’t, users experience that as “the bot is lying”.
One practical decision rule works almost everywhere.
Reversion rate
Users who start with the assistant but immediately revert to a call or ticket.
This is the clearest signal that trust broke mid-conversation.
Fix the highest volume issue that drives reversion first.
The ownership model: one front door, clear owners
“Everyone owns the bot” is how bots rot. Keep accountability crisp.
Virtual Agent Product Owner
Owns adoption, experience quality, backlog, and cadence. Runs the loop.
Journey Owners
Each Core Journey has an accountable owner for the outcome.
Knowledge Owner
Owns content standards, review cycles, and retirement.
Engineering Owner
Owns workflows, approvals, Flow and IntegrationHub, error handling, and reliability.
Risk and controls owner
Owns sensitive topic rules, GenAI guardrails, and audit requirements.
Keep the core loop small: Product Owner, Knowledge, Engineering, Risk. Pull SMEs in when change touches their domain, but don’t outsource ownership.
Content lifecycle: in GenAI, content is the bot
Content is no longer “support”. Content is the bot’s brain.
In the old world, a stale article could be ignored or corrected by a human agent. In a GenAI world, the assistant will read it and present it as truth. That is why knowledge governance is not optional.
Treat knowledge like production code:
• Bot-ready format: short, task-shaped, one outcome, clear prerequisites, clear “when not to use”.
• Two-lens approval: SME accuracy plus experience clarity/safety.
• Publish with expiry: every article has an owner and a review date.
• Trigger refresh from signals: feedback spikes, repeat questions, escalations, known change events.
• Retire aggressively: duplicated, conflicting, or overdue content is removed or quarantined from retrieval.
Escalation rules: trust comes from knowing when to stop
High trust isn’t “never escalate”. It’s “escalate cleanly”.
High risk or low confidence scenarios should hand off fast, with a clean contract.
A good handoff includes intent in one sentence, key facts captured, what was already tried, a recommended queue, and a clear expectation for ownership and response time.
Then measure handoff quality. A bad handoff isn’t an agent problem. It’s a broken loop.
Risk controls for GenAI: make trust explicit
GenAI changes the failure mode. The biggest risk is not that the bot is wrong. It’s that it guesses.
Grounding and source control
Prefer answers grounded in approved knowledge and structured data, and keep the source set intentionally small. If the assistant can’t retrieve an approved source, or the user doesn’t have permission to see it, it should route, clarify, or escalate rather than guess.
Permission aware retrieval
Only retrieve content the user is allowed to see.
Action gating for high assurance work
Some work must stay structured because the cost of being wrong is high. Use GenAI for guidance, but gate execution behind identity, policy, and explicit confirmation.
Basic auditability
Keep it lightweight. Track what changed and how to revert quickly when something drifts.
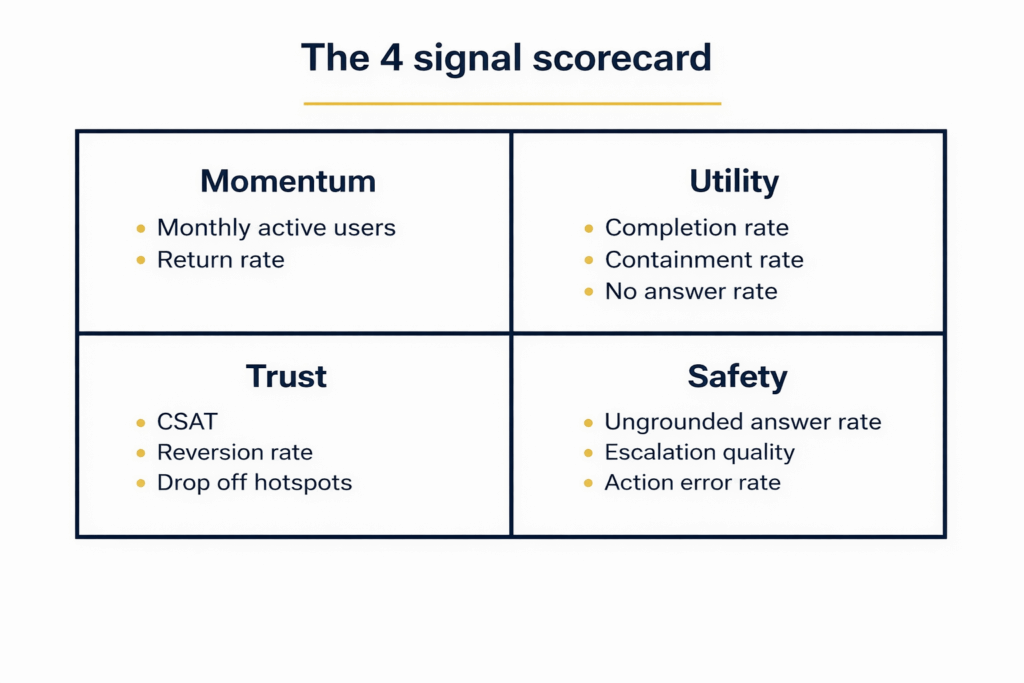
The 4-signal scorecard
Don’t measure everything. Measure four signals that tell you if the loop is working.
Momentum and utility show adoption and outcomes. Trust shows whether users stay in the channel. Safety shows whether the assistant is guessing or escalating well.
Operating cadence: small, frequent improvements
Sustainment is the same discipline as launch. Iterate based on evidence.
Weekly
Review top failures, drop off points, escalation quality, and repeated questions. Fix one high impact issue. Refresh or retire content that triggered negative feedback.
Monthly
Refresh training phrases. Validate routing when the catalogue changes. Regression test automations and permissions. Review the four signals.
Quarterly
Re run intent analysis and select the next Core Journey. Review GenAI sources, prompts, and tool access. Refresh the roadmap and ownership map.
For GenAI
Maintain a small gold set of real queries and expected outcomes, and re run it after any change to prompts, retrieval sources, permissions, or models.
Ending the series
We started this series with a goal: stop forcing humans to speak machine, and start making machines speak human.
Whether you call it the Core Journey, the universal translator, or just good service, the result is the same. Momentum for users, and attention saved for your team.
Bots rot when the loop breaks. Knowledge goes stale. Automations drift. Escalations degrade. The assistant keeps speaking while reality changes underneath it.
If you’re ready to stop building shelfware and start building capability, let’s talk.
Next step: book a Virtual Agent Health Check with Monit Consulting to pinpoint exactly where your loop is broken, and set up a cadence that keeps it healthy after launch.