
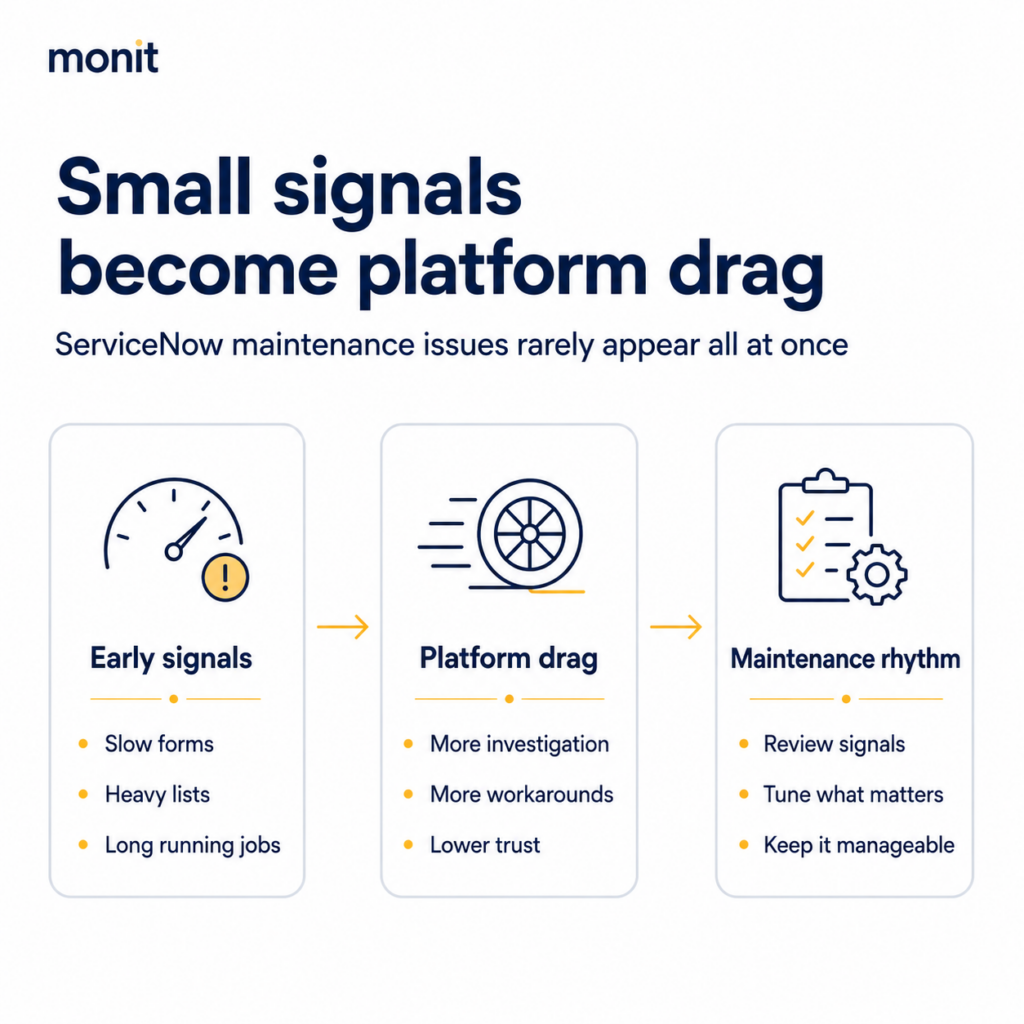
ServiceNow platforms rarely become hard to manage overnight.
It usually happens slowly.
Forms take a little longer to load.
Lists feel heavier than they used to.
Reports take more effort to run.
Scheduled jobs start running longer.
Logs grow without much review.
Old data stays active long after it is useful.
At first, these signs may not feel urgent. The platform still works. Users can still raise tickets. Agents can still update records. Approvals can still move.
But over time, small maintenance issues create drag.
The platform feels slower.
The team spends more time investigating issues.
Users start working around the system.
Admins become reactive instead of proactive.
That is why instance maintenance should not only be seen as technical hygiene.
It is part of platform health.
Slowness is usually a signal
When users say “ServiceNow is slow”, the problem is rarely that simple.
Slowness can come from many places.
It might be the form.
It might be the list view.
It might be the browser.
It might be server processing.
It might be the query behind the page.
It might be a scheduled job or script consuming resources.
That is why vague complaints need to become specific signals.
Which form is slow?
Which list is slow?
Which transaction is taking too long?
Is the delay happening on the server, in the browser, or somewhere else?
Is the issue affecting one area, one node, one user group, or the wider platform?
The goal is not to chase every delay. The goal is to notice patterns early enough to act.
Slow transactions, slow queries, slow scripts and long running jobs can all point to parts of the platform that need attention before the issue becomes a bigger user experience problem.
Indexing needs care
Indexing can improve performance, but it is not something to apply everywhere.
A good index helps the platform retrieve the right data faster. A poor index can add overhead, create confusion, or fail to support the way users actually search and filter.
This is why indexing needs to match real query patterns. Large tables need particular care. Filters that include active records, useful date fields and common search conditions can make a difference, but indexing every field is not the answer.
Text indexing also needs judgement. Some fields are useful to search. Others create noise or processing effort without much value. Fields with generic values, constantly changing values, or values that are better handled through normal filters may not be good candidates.
The bigger point is simple.
Indexes should support the way the platform is actually used. If they do not, they can become part of the maintenance problem rather than the solution.
Forms and lists create everyday friction
Not every maintenance signal sits deep in the platform. Some of the most visible issues appear in everyday work.
A form has too many fields.
A view loads information the user does not need.
A related list pulls back too much data.
A list shows more rows than are useful.
Fields are added because they might be helpful, not because they support the task.
Each decision may seem small. Together, they affect how the platform feels.
For agents and fulfilment teams, slow forms and heavy lists are not minor annoyances. They add friction to every interaction. They slow down updates, increase frustration and make the platform feel harder to use.
This is why form design is also a maintainability issue.
Good form views should support the task.
They should avoid unnecessary fields.
They should use related lists carefully.
They should consider whether some information belongs in a separate view rather than being loaded for everyone.
A cleaner form is not only better design. It is often better performance.
Logs, jobs and old data need routine review
Maintenance also depends on the signals teams review behind the scenes.
Long running scheduled jobs can point to inefficient scripts, large table queries, or background work that needs tuning. Repeated errors can show where something is failing quietly. Large log files can suggest excessive logging, especially when debug style statements remain active longer than they should.
Old data can also create avoidable weight.
If email data, historical records, logs or inactive operational data are kept without a clear retention approach, the platform can carry more than it needs. Data archiving, database rotation and retention decisions may not feel exciting, but they matter.
They help reduce unnecessary load and keep the platform easier to manage.
The key is routine. These signals should not only be reviewed when something breaks. They should be part of how the platform is operated.
Maintenance is a capability issue
Instance maintenance is often treated as an admin task. But for growing ServiceNow environments, it is also a capability issue.
A strong platform team does not only build new features and respond to requests. It also has a rhythm for keeping the platform healthy.
That means asking:
• Who reviews slow transactions and slow queries?
• How often are long running jobs checked?
• Are form views reviewed for usability and performance?
• Are related lists being used carefully?
• Are indexes reviewed against real query patterns?
• Is old data being retained, archived or removed with intent?
• Are repeated errors investigated before they become normal?
These questions are not about perfection. They are about ownership.
If nobody owns maintenance signals, the platform can still run, but become harder to trust and harder to support.
The goal is not to optimise everything
Not every slow page is a crisis. Not every old record needs to be archived immediately. Not every query needs a new index.
The goal is not to optimise everything.
The goal is to know when the platform is becoming heavier, slower or harder to manage.
That visibility gives the team more control. It helps them spot patterns earlier, prioritise the right fixes, reduce avoidable friction, and maintain trust in the platform as it grows.
ServiceNow maintenance is not just about cleaning up technical issues. It is about protecting the platform’s ability to keep supporting work without creating unnecessary drag.
A healthy platform is not only one that is available. It is one that remains maintainable as it grows.
If ServiceNow feels slower, heavier or harder to support over time, Monit’s Team Capability Assessment can help. It assesses the team practices, governance and operating rhythm needed to maintain platform health.