
A ServiceNow platform can be online and still be unhealthy.
Users can log in.
Tickets can be raised.
Approvals can move.
Reports can load.
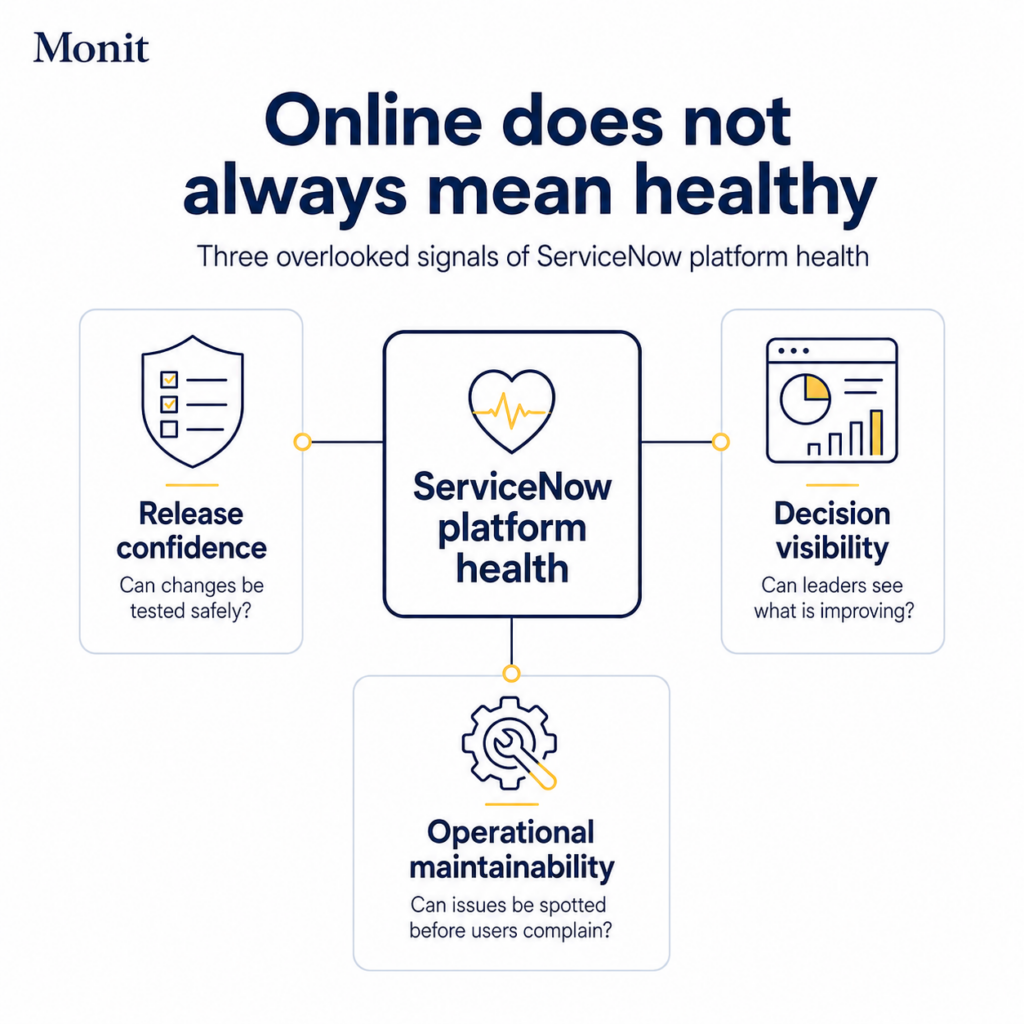
But underneath that, the platform may be getting harder to change, harder to measure, and harder to maintain.
That is why platform health should not only be viewed through uptime or availability. Those things matter, but they do not tell the full story.
For platform teams, health also shows up in quieter signals.
Can important changes be tested with confidence?
Can leaders see whether service management is improving?
Can the team spot performance and maintenance issues before users start complaining?
Three signals are often overlooked:
• release confidence
• decision visibility
• operational maintainability
1. Release confidence
As ServiceNow grows, change becomes harder to validate.
A workflow change may affect approvals, notifications, roles, integrations, reports, or downstream processes. An upgrade may require teams to check critical journeys across multiple modules. A custom application may work well on its own, but still create risk when the platform changes around it.
This is where Automated Test Framework can become valuable. ATF is not just a testing tool. Used well, it supports release confidence.
It helps platform teams validate important processes in a consistent and repeatable way. It can support upgrade testing, regression checks, functional testing, and business logic testing across key workflows.
The real value is not only automation. It is confidence.
Confidence that critical processes still work after change.
Confidence that validation is not being rebuilt from scratch each time.
Confidence that testing does not depend only on one or two people remembering what to check.
That does not mean every organisation needs a large ATF setup.
But it is worth asking:
• How many modules are we using?
• How many custom applications do we support?
• How many integrations rely on stable workflows?
• How much manual validation happens during upgrades or releases?
• Are we testing consistently, or relying on individual knowledge?
When testing depends too heavily on memory, platform risk quietly grows. A healthy platform should not make every release feel like a fresh investigation.
2. Decision visibility
Reporting is often treated as an output of the platform.
Tickets closed.
Incidents resolved.
Requests completed.
SLA performance tracked.
Those reports are useful, but they are not always enough.
The stronger question is not simply, “What happened?”
It is: “What are we trying to improve, and can we see whether it is working?”
That is where decision visibility matters.
Good reporting should connect to service management objectives. It should help leaders understand where friction exists, which processes influence outcomes, and whether improvement work is actually changing the experience.
This is where leading and lagging indicators become useful.
• Lagging indicators show the result. They are often easier to measure, but harder to influence.
• Leading indicators show the behaviours or process inputs that shape the result. They are usually harder to define, but more useful for improvement.
For example, resolution time may show how long work took.
But intake quality, reassignment rates, categorisation accuracy, approval delays, and repeated follow up questions may show whether the process is becoming healthier before the final outcome appears.
A platform can have many reports and still lack useful visibility. Healthy reporting should help teams make better decisions, not just describe workload after the fact.
3. Operational maintainability
Maintainability is one of the quieter signs of platform health. It often shows up in small signals first.
Forms take longer to load.
Lists feel heavy.
Related lists pull back more data than users need.
Indexes are missing, excessive, or poorly matched to how people search.
Scheduled jobs run longer than expected.
Logs grow without review.
Old data remains active even when it is no longer useful.
Slow transactions become normal.
None of these signs may feel urgent on their own. But together, they create drag.
Users experience the platform as slower. Agents work around delays. Admins spend more time investigating issues. Platform teams become reactive because maintenance only gets attention after something becomes visible enough to complain about.
A healthier pattern is to treat maintenance as part of normal platform ownership.
That means regularly reviewing signals such as:
• slow transactions
• slow queries
• slow scripts
• form load times
• list response times
• long running scheduled jobs
• text indexing performance
• log growth
• data retention and archiving
• unnecessary fields and related lists
The goal is not to optimise everything. The goal is to notice when the platform is becoming harder to operate.
Platform health is also a capability issue
These three signals are not only technical. They say something about how the platform is being managed.
If testing is inconsistent, release confidence drops.
If reporting does not support decisions, improvement becomes harder to steer.
If maintenance signals are ignored, the platform becomes slower and more difficult to support.
This is why platform health should be seen as part of platform capability.
A strong platform team does not only deliver new work. It also creates the conditions for safe change, useful visibility, and sustainable operation.
That requires ownership.
It requires routines.
It requires time.
It requires the right skills and governance around the platform.
Without those things, the platform may continue running, but the team behind it can become increasingly reactive.
Is the platform still manageable as it grows?
For many organisations, ServiceNow becomes central to how work is requested, routed, approved, measured, and delivered.
So platform health cannot only mean availability.
It also means the platform can be changed safely, measured usefully, and maintained without constant reactive effort.
That is why release confidence, decision visibility, and operational maintainability matter.
They show whether the platform is simply running, or whether it is being managed well enough to support what comes next.
A healthy platform needs more than uptime. It needs the right capability around it.
If you are unsure whether your ServiceNow platform is still manageable as it grows, Monit’s Team Capability Assessment can help assess the team, governance, and operating rhythm needed to support safe change, useful visibility, sustainable maintenance, and roadmap delivery.